

Seismic data quality means having the solid foundation of a complete reliable dataset in your subsurface database, an ongoing quest for oil and gas companies. How can you stand behind your projects and investments if you’re not certain that they’re built upon quality seismic and well data?
Oil and gas companies with assets in multiple countries around the world manage many petabytes of seismic and well data. If there are data quality issues, it can become overwhelming to know how to go about addressing the big scary monster of discrepancies that could be hidden within massive volumes of subsurface data. However, poor data quality will lead to frustrated geoscientists, and perhaps incorrect interpretations and business decisions – so they do need to be fixed.
Let’s look at some practical, methodical approaches to ensure that your subsurface data quality is solid and accurate.
Seismic Data Quality – A Definition
What do we mean by seismic data quality? The Data Management Body of Knowledge (DMBOK) defines data quality as:
“The measure to which data is fit for consumption and meets the needs of data consumers.”
In other words, the quality of data is determined by the extent to which the data is capable of giving you the insight you should get from it. As an example, if someone was applying for a mortgage, they may do a very rapid and rough calculation in order to determine whether or not they could afford the house they were interested in. While this data may be useful, it would not be high enough quality to actually qualify for a mortgage.
In the oil and gas industry, companies often access sparse datasets and do quick interpretations in order to prepare for licensing rounds. While this offers insight necessary to target areas of interest, neither the data nor the interpretation are high enough quality to plan an actual well.
Quality seismic data is also trustworthy. When you look at a stock ticker, you never feel like you have to double check a share price somewhere else, you just trust that it’s accurate. Having that same trust for your subsurface data is important. Trustworthy subsurface data is a product of internal processes, such as established data standards, governance, accountability and consistency. Having these makes your geoscientists better able to make good decisions, and also makes sharing data internally, or between companies easier.
Fixing Forever, Not Forever Fixing
Let’s play out a scenario: an organization is working a new area, so the geoscientists go to the public data sources for data. As they pull the subsurface data, they spend time ‘fixing’ it: normalizing and splicing curves, balancing seismic sections etc., and loading the ‘fixed’ data into their interpretation environment. At the end of the process, the company makes the decision not to pursue further activity in the area. All of the work is halted and perhaps some of the interpretation is stored on a shared drive somewhere.
Five years later, the economics change and the company re-enters the area. But the knowledge and previous work has been lost and the company starts the whole process over by re-accessing the same public data as before. As an industry, we repeatedly fix the same data multiple times, and oil and gas companies go through this cycle of forever fixing data.
The challenge for companies is to move away from forever fixing data to fixing forever. Proper data management practices will allow you to fix data once and use that quality data for decision-making. Quality data represents your assets and supports the value of your corporation, whether it’s reserves calculations, well plans and inventories, or reservoir models.
Dimensions of Seismic Data Quality
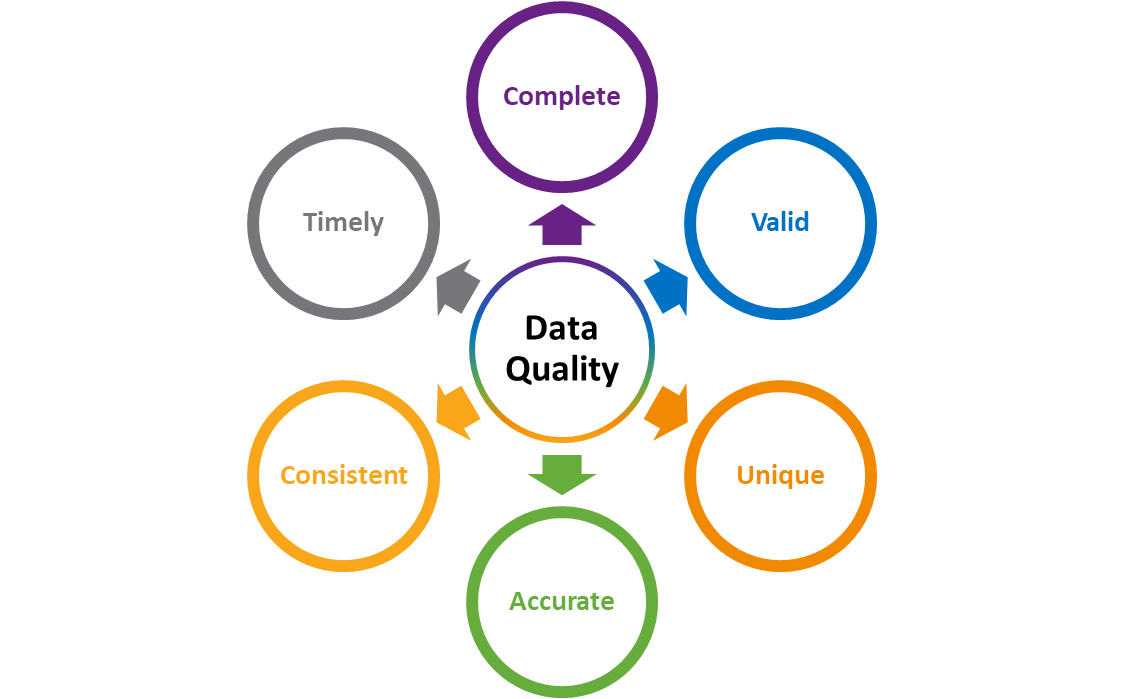
Data quality can be broken down into six essential dimensions:
- Is my data complete?
- Is my data valid?
- Is my data unique?
- Is my data accurate?
- Is my data consistent?
- Is my data timely?
Is my data complete?
What do we mean by ‘complete?’ The completeness of a dataset is determined by what you need it for. For example, if you want to reprocess some seismic data, you will need to have field tapes, observer’s logs and navigation data. You wouldn’t need the stacked data, so although that would certainly be necessary if you wanted to interpret the data, it isn’t part of the complete dataset for processing. Measuring data completeness is a process of determining whether you have everything you need to effectively use the data for its intended purpose.
Is my data valid?
Once you understand the completeness of your data, the next thing to look at is data validity. Checking data validity is really about doing a ‘sense check.’ Does the value make sense? Are the units right? Is the start date is actually before the end date?
Establishing basic business and data rules allows you to measure your data validity in your database, and a great place to start is the base set of data rules from PPDM (Professional Petroleum Data Management Association). In collaboration with the industry, the PPDM established a set of business data rules that were created with the idea of “what gets measured gets managed” (quote by Peter Drucker). Additional PPDM resources like “What is a well?” and “What is a completion?” establish standard terminology and can help you determine what is valid to your organization.
Is my data unique?
A running joke in the data management domain is: “How many ‘line ones’ are in your seismic database?” Funny or not, some organizations can have up to 500 seismic lines with the same name!
Duplicates don’t have to have the same name, either. Analyzing your data spatially is the first step to removing duplicates from your databases. When you incorporate metadata into the spatial analysis, you can identify problem data and fix a duplicate data point.
Is my data accurate?
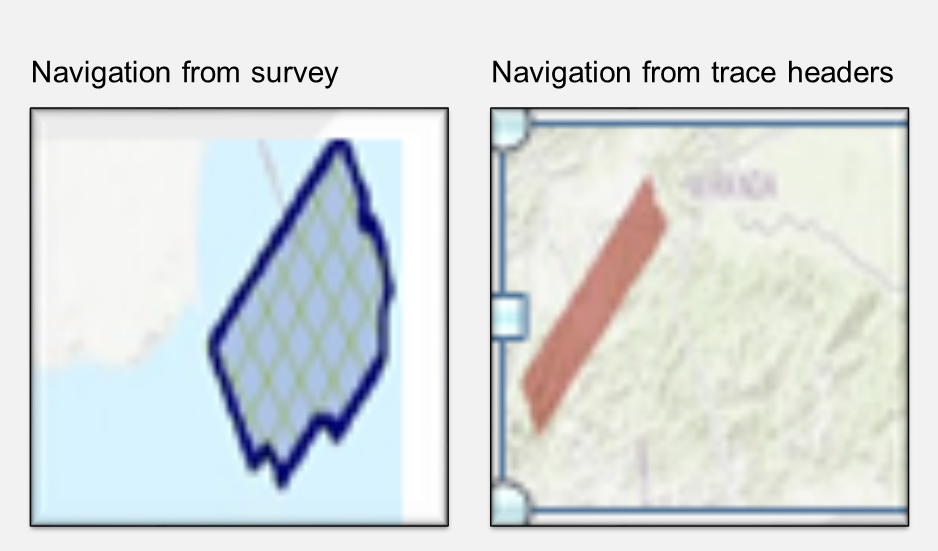
In the photo below, the left side shows a bin map that was loaded based on the navigation file that came with the survey, and the image on the right side shows the location based on the navigation data pulled from the trace headers. One appears to be in the ocean, while the other one is not.
Questions to ask regarding data accuracy include:
- Is the data projecting properly?
- Does the XY data match the latitude/longitudes?
Is my data consistent?
Some say that it’s okay to be wrong, as long as everything is wrong in context. In other words, it’s ok if something is wrong as long as everything is wrong in the same way. A North American example is the old map survey datum known as NAD 27 (North American Datum 1927). It’s out of date and has been replaced by a new datum called NAD 83 (North American Datum 1983). But many companies retain the use of NAD 27 and ensure that everything is projected with it.
Related content:
Is my data timely?
How long does it take your data to get to your geoscientist’s desk? If you were doing a bid round and have three weeks to put the data together, evaluate the data and determine if you are going to invest in the project, and it takes two weeks and six days to get the data to your geoscientists, that’s not good enough.
Organizational processes and technology are constantly evolving to improve efficiency and performance. For example, if you are logging a well, the logging company could drop the log data to a Dropbox, where automated processes can load it to your subsurface databases. By the time your geoscientists get to work in the morning, the data would be available anywhere with an internet connection; their phone, field truck, desktop or home office.
People, process, technology
The infrastructure required to maintain data quality and protect all of the data relies upon the people, process and technology within your organization. Experienced people will define the rules for each quality dimension, and processes are built around them. Technology, such as the iGlass data quality module, can measure the state of your data by testing data rules against it. Additionally, the data quality module has a set of tools to detect quality issues and provides a starting point for data stewards to make suitable corrections. You can run your data quality rules on demand or an automated basis, continually monitoring the state of your subsurface data.
Data quality is crucial to data analytics, and the newly released Katalyst 360 analytics platform provides a 360 view of the subsurface data quality issues that may be prevalent across an organization. In the case of data completeness, Katalyst 360 can help you identify missing data, such as seismic lines without field, stack or navigation data.
Related content:
The Big Scary Monster
With the right people, processes and technology, the big scary monster of data management is not so terrifying. You can easily measure and score data quality, create action plans and break the work down into manageable projects. There are many tools to help you get started, and dashboards are available to monitor the improvements and the progress in data quality.
The importance of subsurface data quality cannot be overstated. The quality measures that take place behind the scenes create a solid foundation for data management technology and processes, and enable analytics such as Katalyst 360.
If you would like more information on how to improve and manage your subsurface data quality, please contact us.
Contact Us
Let us help you work through subsurface data quality concerns. Complete the form below and one of our team members will contact you promptly.